AlgorithmTruncated Policy IterationInput: Probability models p(r∣s,a) and p(s′∣s,a), max iterations jtruncate.Initialization: Initial guess π0.While vk not converged:Policy Evaluation:Initialize: vk(0) arbitrarily.For j=0 to jtruncate−1:For each s∈S:vk(j+1)(s)←a∑πk(a∣s)[r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vk(j)(s′)]vk←vk(jtruncate)(Update value function)Policy Improvement:For each s∈S:For each a∈A(s):qk(s,a)←r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vk(s′)(Q-computation)ak∗(s)←argamaxqk(s,a)(Greedy selection)πk+1(a∣s)←{10if a=ak∗(s)otherwise(Policy update)
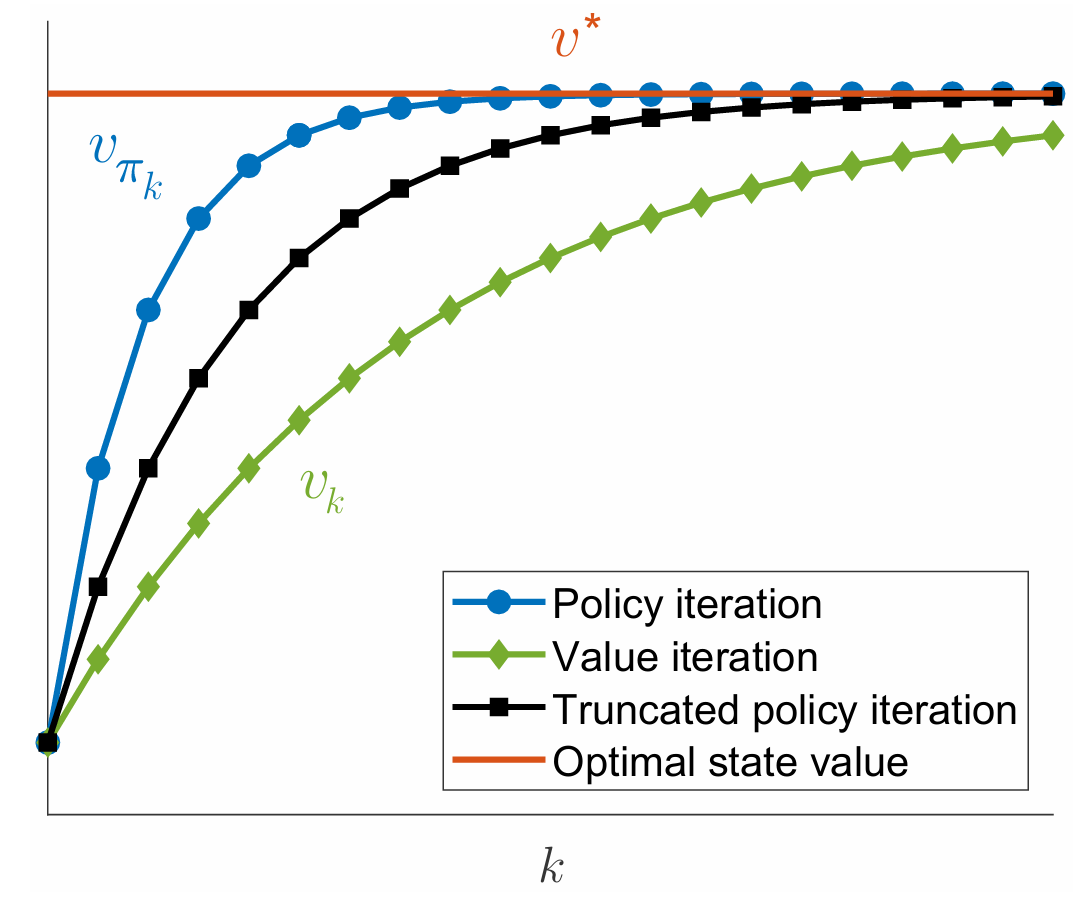
Policy Iteration(PI) vs. Value Iteration(VI) vs. Trucated Policy Iteration(TPI)